
前言
本专题旨在快速了解常见的数据结构和算法。
在需要使用到相应算法时,能够帮助你回忆出常用的实现方案并且知晓其优缺点和适用环境。并不涉及十分具体的实现细节描述。
图的最短路径算法
最短路径问题是图论研究中的一个经典算法问题,旨在寻找图(由结点和路径组成的)中两结点之间的最短路径。
算法具体的形式包括:
- 确定起点的最短路径问题:即已知起始结点,求最短路径的问题。适合使用Dijkstra算法。
- 确定终点的最短路径问题:与确定起点的问题相反,该问题是已知终结结点,求最短路径的问题。在无向图中该问题与确定起点的问题完全等同,在有向图中该问题等同于把所有路径方向反转的确定起点的问题。
- 确定起点终点的最短路径问题:即已知起点和终点,求两结点之间的最短路径。
- 全局最短路径问题:求图中所有的最短路径。适合使用Floyd-Warshall算法。
主要介绍以下几种算法:
- Dijkstra最短路算法(单源最短路)
- Bellman–Ford算法(解决负权边问题)
- SPFA算法(Bellman-Ford算法改进版本)
- Floyd最短路算法(全局/多源最短路)
常用算法
Dijkstra最短路算法(单源最短路)
图片例子和史料来自:http://blog.51cto.com/ahalei/1387799
算法介绍:
迪科斯彻算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树。该算法常用于路由算法或者作为其他图算法的一个子模块。
指定一个起始点(源点)到其余各个顶点的最短路径,也叫做“单源最短路径”。例如求下图中的1号顶点到2、3、4、5、6号顶点的最短路径。
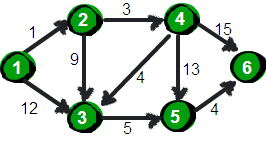
使用二维数组e来存储顶点之间边的关系,初始值如下。
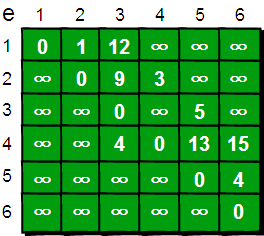
我们还需要用一个一维数组dis来存储1号顶点到其余各个顶点的初始路程,如下。

将此时dis数组中的值称为最短路的“估计值”。
既然是求1号顶点到其余各个顶点的最短路程,那就先找一个离1号顶点最近的顶点。通过数组dis可知当前离1号顶点最近是2号顶点。当选择了2号顶点后,dis[2]的值就已经从“估计值”变为了“确定值”,即1号顶点到2号顶点的最短路程就是当前dis[2]值。
既然选了2号顶点,接下来再来看2号顶点有哪些出边呢。有2->3和2->4这两条边。先讨论通过2->3这条边能否让1号顶点到3号顶点的路程变短。也就是说现在来比较dis[3]和dis[2]+e[2][3]的大小。其中dis[3]表示1号顶点到3号顶点的路程。dis[2]+e[2][3]中dis[2]表示1号顶点到2号顶点的路程,e[2][3]表示2->3这条边。所以dis[2]+e[2][3]就表示从1号顶点先到2号顶点,再通过2->3这条边,到达3号顶点的路程。
这个过程有个专业术语叫做“松弛”。松弛完毕之后dis数组为:
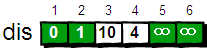
接下来,继续在剩下的3、4、5和6号顶点中,选出离1号顶点最近的顶点4,变为确定值,以此类推。
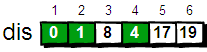
最终dis数组如下,这便是1号顶点到其余各个顶点的最短路径。

核心代码:
1 | //Dijkstra算法核心语句 |
关于复杂度:
- M:边的数量
- N:节点数量
通过上面的代码我们可以看出,我们实现的Dijkstra最短路算法的时间复杂度是O(N^2)。其中每次找到离1号顶点最近的顶点的时间复杂度是O(N)。
优化:
这里我们可以用“堆”(以后再说)来优化,使得这一部分的时间复杂度降低到
O(logN)。另外对于边数M少于
N^2的稀疏图来说(我们把M远小于N^2的图称为稀疏图,而M相对较大的图称为稠密图),我们可以用邻接表来代替邻接矩阵,使得整个时间复杂度优化到O((M+N)logN)。请注意!在最坏的情况下M就是
N^2,这样的话MlogN要比N^2还要大。但是大多数情况下并不会有那么多边,因此(M+N)logN要比N^2小很多。
Dijkstra思想总结:
dijkstra算法本质上算是贪心的思想,每次在剩余节点中找到离起点最近的节点放到队列中,并用来更新剩下的节点的距离,再将它标记上表示已经找到到它的最短路径,以后不用更新它了。这样做的原因是到一个节点的最短路径必然会经过比它离起点更近的节点,而如果一个节点的当前距离值比任何剩余节点都小,那么当前的距离值一定是最小的。(剩余节点的距离值只能用当前剩余节点来更新,因为求出了最短路的节点之前已经更新过了)
dijkstra就是这样不断从剩余节点中拿出一个可以确定最短路径的节点最终求得从起点到每个节点的最短距离。
用邻接表代替邻接矩阵存储
参考:http://blog.51cto.com/ahalei/1391988
总结如下:
可以发现使用邻接表来存储图的时间空间复杂度是O(M),遍历每一条边的时间复杂度是也是O(M)。如果一个图是稀疏图的话,M要远小于N^2。因此稀疏图选用邻接表来存储要比邻接矩阵来存储要好很多。
Bellman–Ford算法(解决负权边问题)
思想:
bellman-ford算法进行n-1次更新(一次更新是指用所有节点进行一次松弛操作)来找到到所有节点的单源最短路。
bellman-ford算法和dijkstra其实有点相似,该算法能够保证每更新一次都能确定一个节点的最短路,但与dijkstra不同的是,并不知道是那个节点的最短路被确定了,只是知道比上次多确定一个,这样进行n-1次更新后所有节点的最短路都确定了(源点的距离本来就是确定的)。
现在来说明为什么每次更新都能多找到一个能确定最短路的节点:
1 | 1.将所有节点分为两类:已知最短距离的节点和剩余节点。 |
bellman-ford的一个优势是可以用来判断是否存在负环,在不存在负环的情况下,进行了n-1次所有边的更新操作后每个节点的最短距离都确定了,再用所有边去更新一次不会改变结果。而如果存在负环,最后再更新一次会改变结果。原因是之前是假定了起点的最短距离是确定的并且是最短的,而又负环的情况下这个假设不再成立。
Bellman-Ford 算法描述:
- 创建源顶点 v 到图中所有顶点的距离的集合 distSet,为图中的所有顶点指定一个距离值,初始均为 Infinite,源顶点距离为 0;
- 计算最短路径,执行 V - 1 次遍历;
- 对于图中的每条边:如果起点 u 的距离 d 加上边的权值 w 小于终点 v 的距离 d,则更新终点 v 的距离值 d;
- 检测图中是否有负权边形成了环,遍历图中的所有边,计算 u 至 v 的距离,如果对于 v 存在更小的距离,则说明存在环;
伪代码:
1 | BELLMAN-FORD(G, w, s) |
SPFA(Bellman-Ford算法改进版本)
SPFA算法是1994年西安交通大学段凡丁提出
spfa可以看成是bellman-ford的队列优化版本,正如在前面讲到的,bellman每一轮用所有边来进行松弛操作可以多确定一个点的最短路径,但是用每次都把所有边拿来松弛太浪费了,不难发现,只有那些已经确定了最短路径的点所连出去的边才是有效的,因为新确定的点一定要先通过已知(最短路径的)节点。
所以我们只需要把已知节点连出去的边用来松弛就行了,但是问题是我们并不知道哪些点是已知节点,不过我们可以放宽一下条件,找哪些可能是已知节点的点,也就是之前松弛后更新的点,已知节点必然在这些点中。
所以spfa的做法就是把每次更新了的点放到队列中记录下来。
伪代码:
1 | ProcedureSPFA; |
如何看待 SPFA 算法已死这种说法?
来自:https://www.zhihu.com/question/292283275/answer/484694411
在非负边权的图中,随手卡 SPFA 已是业界常识。在负边权的图中,不把 SPFA 卡到最慢就设定时限是非常不负责任的行为,而卡到最慢就意味着 SPFA 和传统 Bellman Ford 算法的时间效率类似,而后者的实现难度远低于前者。
Floyd最短路算法(全局/多源最短路)
图片例子和史料来自:https://www.cnblogs.com/ahalei/p/3622328.html
此算法由Robert W. Floyd(罗伯特·弗洛伊德)于1962年发表在“Communications of the ACM”上。同年Stephen Warshall(史蒂芬·沃舍尔)也独立发表了这个算法。Robert W.Floyd这个牛人是朵奇葩,他原本在芝加哥大学读的文学,但是因为当时美国经济不太景气,找工作比较困难,无奈之下到西屋电气公司当了一名计算机操作员,在IBM650机房值夜班,并由此开始了他的计算机生涯。此外他还和J.W.J. Williams(威廉姆斯)于1964年共同发明了著名的堆排序算法HEAPSORT。
算法介绍:
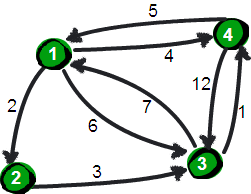
上图中有4个城市8条公路,公路上的数字表示这条公路的长短。请注意这些公路是单向的。我们现在需要求任意两个城市之间的最短路程,也就是求任意两个点之间的最短路径。这个问题这也被称为“多源最短路径”问题。
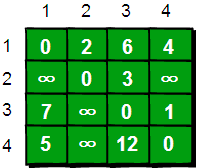
现在需要一个数据结构来存储图的信息,我们仍然可以用一个4*4的矩阵(二维数组e)来存储。
核心代码:
1 | for(k=1;k<=n;k++) |
这段代码的基本思想就是:
最开始只允许经过1号顶点进行中转,接下来只允许经过1和2号顶点进行中转……允许经过1~n号所有顶点进行中转,求任意两点之间的最短路程。一旦发现比之前矩阵内存储的距离短,就用它覆盖原来保存的距离。
用一句话概括就是:从i号顶点到j号顶点只经过前k号点的最短路程。
另外需要注意的是:Floyd-Warshall算法不能解决带有“负权回路”(或者叫“负权环”)的图,因为带有“负权回路”的图没有最短路。例如下面这个图就不存在1号顶点到3号顶点的最短路径。因为1->2->3->1->2->3->…->1->2->3这样路径中,每绕一次1->-2>3这样的环,最短路就会减少1,永远找不到最短路。其实如果一个图中带有“负权回路”那么这个图则没有最短路。
代码实现:
1 | #include <stdio.h> |
总结
关于BellmanFord和SPFA再说两句
来自:https://www.zhihu.com/question/27312074
SPFA只是BellmanFord的一种优化,其复杂度是O(kE),SPFA的提出者认为k很小,可以看作是常数,但事实上这一说法十分不严谨(原论文的“证明”竟然是靠编程验证,甚至没有说明编程验证使用的数据是如何生成的),如其他答案所说的,在一些数据中,这个k可能会很大。而Dijkstra算法在使用斐波那契堆优化的情况下复杂度是O(E+VlogV)。SPFA,或者说BellmanFord及其各种优化(姜碧野的国家集训队论文就提到了一种栈的优化)的优势更主要体现在能够处理负权和判断负环吧(BellmanFord可以找到负环,但SPFA只能判断负环是否存在)。
补充算法
还有一些最短路算法的优化或者引申方法,感兴趣可以谷歌一下:
- Johnson算法
- Bi-Direction BFS算法
- …
参考
- 算法第四版第4章4.4最短路径
- https://www.cnblogs.com/ahalei/p/3622328.html
- http://blog.51cto.com/ahalei/1387799
- 啊哈算法
- https://blog.csdn.net/qq_35644234/article/details/60870719
- https://blog.csdn.net/mmy1996/article/details/52225893
- http://www.cnblogs.com/gaochundong/p/bellman_ford_algorithm.html
关注我
我目前是一名后端开发工程师。技术领域主要关注后端开发,数据安全,爬虫,5G物联网等方向。
微信:yangzd1102
Github:@qqxx6661
个人博客:
- CSDN:@Rude3Knife
- 知乎:@Zhendong
- 简书:@蛮三刀把刀
- 掘金:@蛮三刀把刀
原创博客主要内容
- Java知识点复习全手册
- Leetcode算法题解析
- 剑指offer算法题解析
- SpringCloud菜鸟入门实战系列
- SpringBoot菜鸟入门实战系列
- Python爬虫相关技术文章
- 后端开发相关技术文章
个人公众号:Rude3Knife

如果文章对你有帮助,不妨收藏起来并转发给您的朋友们~