
前言
本文快速回顾了常考的知识点,用作面试复习,事半功倍。
面试知识点复习手册
通过以下两种途径查看全复习手册文章导航
- 关注我的公众号:Rude3Knife 点击公众号下方:技术推文——面试冲刺
- 全复习手册文章导航(CSDN)
本文参考
十道海量数据处理面试题与十个方法大总结
https://blog.csdn.net/v_july_v/article/details/6279498
重点:十七道海量数据处理面试题与Bit-map详解
https://blog.csdn.net/v_july_v/article/details/6685962
有删减,修改,补充额外增加内容
本作品采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可。
—–正文开始—–
预备知识点
Bitmap和布隆过滤器(Bloom Filter)
https://blog.csdn.net/zdxiq000/article/details/57626464
Bitmap
我们只想知道某个元素出现过没有。如果为每个所有可能的值分配1个bit,32bit的int所有可能取值需要内存空间为:
2^32bit=2^29Byte=512MB
但对于海量的、取值分布很均匀的集合进行去重,Bitmap极大地压缩了所需要的内存空间。于此同时,还额外地完成了对原始数组的排序工作。缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
Bloom Filter
如果说Bitmap对于每一个可能的整型值,通过直接寻址的方式进行映射,相当于使用了一个哈希函数,那布隆过滤器就是引入了k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。下图中是k=3时的布隆过滤器。
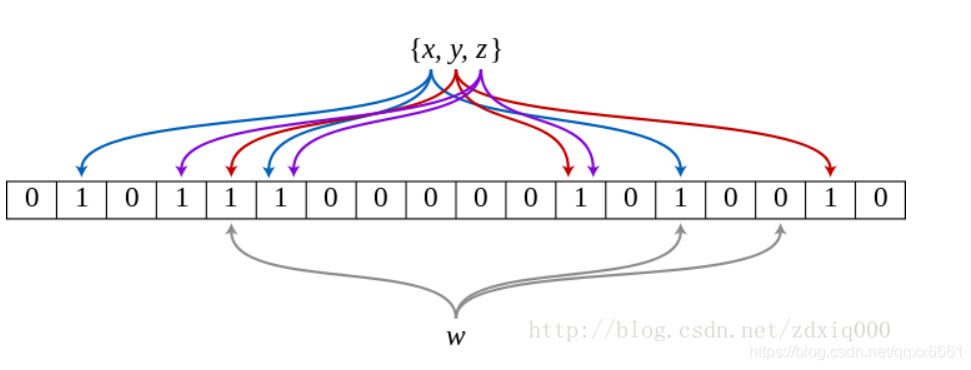
那么布隆过滤器的误差有多少?我们假设所有哈希函数散列足够均匀,散列后落到Bitmap每个位置的概率均等。
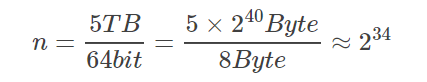
若以m=16nm=16n计算,Bitmap集合的大小为238bit=235Byte=32GB238bit=235Byte=32GB,此时的ε≈0.0005。并且要知道,以上计算的都是误差的上限。
布隆过滤器通过引入一定错误率,使得海量数据判重在可以接受的内存代价中得以实现。从上面的公式可以看出,随着集合中的元素不断输入过滤器中(nn增大),误差将越来越大。但是,当Bitmap的大小mm(指bit数)足够大时,比如比所有可能出现的不重复元素个数还要大10倍以上时,错误概率是可以接受的。
这里有一个google实现的布隆过滤器,我们来看看它的误判率:
在这个实现中,Bitmap的集合m、输入的原始数集合n、哈希函数k的取值都是按照上面最优的方案选取的,默认情况下保证误判率ε=0.5k<0.03≈0.55,因而此时k=5。
而还有一个很有趣的地方是,实际使用的却并不是5个哈希函数。实际进行映射时,而是分别使用了一个64bit哈希函数的高、低32bit进行循环移位。注释中包含着这个算法的论文“Less Hashing, Same Performance: Building a Better Bloom Filter”,论文中指明其对过滤器性能没有明显影响。很明显这个实现对于m>232时的支持并不好,因为当大于231−1的下标在算法中并不能被映射到。
海量数据问题解题思路
参考:https://blog.csdn.net/luochoudan/article/details/53736752
个人将这些题分成了两类:一类是容易写代码实现的;另一类侧重考察思路的。毫无疑问,后一种比较简单,你只要记住它的应用场景、解决思路,并能在面试的过程中将它顺利地表达出来,便能以不变应万变。前一种,需要手写代码,就必须要掌握一定的技巧,常见的解法有两种,就是前面说过的堆排和快排的变形。
- 堆排序:我认为不用变形,会原始堆排序就行。
- 快排变形(找到最大的TopK): 当len(ary) - K == key or len(ary) - K == key + 1时就得到了最大的K个数。
注意点:
- 分小文件:hash后直接存储原来的值,而不是将hash值分到各个文件中。
- 单位换算:一字节8bit
经典题目:
序号对应于参考网页:
https://blog.csdn.net/v_july_v/article/details/6685962
hash后将海量数据分到另外的小文件中,分别处理,最后再归并
1.2.3.4.7.8.11.13
经典例题:2
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(,此处有误,更正为b0,b1,b2,b9)。
对这10个文件进行归并排序(内排序与外排序相结合)。方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了
bitmap直接映射
经典例题:5
在2.5亿个整数中找出不重复的整数,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32*2bit=1GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用上题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
最大最小堆
经典例题:6
海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
桶排序
经典例题:15
给定n个实数,求着n个实数在实轴上向量2个数之间的最大差值,要求线性的时间算法。
方案1:最先想到的方法就是先对这n个数据进行排序,然后一遍扫描即可确定相邻的最大间隙。但该方法不能满足线性时间的要求。故采取如下方法:
- 找到n个数据中最大和最小数据max和min。
- 用n-2个点等分区间[min, max],即将[min, max]等分为n-1个区间(前闭后开区间),将这些区间看作桶,编号为,且桶i 的上界和桶i+1的下届相同,即每个桶的大小相同。每个桶的大小为:。实际上,这些桶的边界构成了一个等差数列(首项为min,公差为),且认为将min放入第一个桶,将max放入第n-1个桶。
- 将n个数放入n-1个桶中:将每个元素x[i] 分配到某个桶(编号为index),其中(这括号里多了个“+”),并求出分到每个桶的最大最小数据。
- 最大间隙:除最大最小数据max和min以外的n-2个数据放入n-1个桶中,由抽屉原理可知至少有一个桶是空的,又因为每个桶的大小相同,所以最大间隙不会在同一桶中出现,一定是某个桶的上界和气候某个桶的下界之间隙,且该量筒之间的桶(即便好在该连个便好之间的桶)一定是空桶。也就是说,最大间隙在桶i的上界和桶j的下界之间产生j>=i+1。一遍扫描即可完成。
并查集
经典例题:16
TopK问题(注重代码实现)
经典例题:12
100w个数中找出最大的100个数。
方案1:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w100)。
方案3:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100wlg100)。
字典树Tire树
经典例题:3.9.10
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案1:顺序读文件中,对于每个词x,取,然后按照该值存到5000个小文件(记为)中。这样每个文件大概是200k左右。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
求中位数
经典例题:14
一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数中的中数?
方案1:先大体估计一下这些数的范围,比如这里假设这些数都是32位无符号整数(共有2^32个)。我们把0到2^32-1的整数划分为N个范围段,每个段包含(2^32)/N个整数。比如,第一个段位0到2^32/N-1,第二段为(2^32)/N到(2^32)/N-1,…,第N个段为(2^32)(N-1)/N到2^32-1。然后,扫描每个机器上的N个数,把属于第一个区段的数放到第一个机器上,属于第二个区段的数放到第二个机器上,…,属于第N个区段的数放到第N个机器上。注意这个过程每个机器上存储的数应该是O(N)的。下面我们依次统计每个机器上数的个数,一次累加,直到找到第k个机器,在该机器上累加的数大于或等于(N^2)/2,而在第k-1个机器上的累加数小于(N^2)/2,并把这个数记为x。那么我们要找的中位数在第k个机器中,排在第(N^2)/2-x位。然后我们对第k个机器的数排序,并找出第(N^2)/2-x个数,即为所求的中位数的复杂度是O(N^2)的。
方案2:先对每台机器上的数进行排序。排好序后,我们采用归并排序的思想,将这N个机器上的数归并起来得到最终的排序。找到第(N^2)/2个便是所求。复杂度是O(N^2*lgN^2)的。
补充题目:在10G的数据中找出中位数
不妨假设10G个整数是64bit的。
2G内存可以存放256M个64bit整数。
我们可以将64bit的整数空间平均分成256M个取值范围,用2G的内存对每个取值范围内出现整数个数进行统计。这样遍历一边10G整数后,我们便知道中数在那个范围内出现,以及这个范围内总共出现了多少个整数。
如果中数所在范围出现的整数比较少,我们就可以对这个范围内的整数进行排序,找到中数。如果这个范围内出现的整数比较多,我们还可以采用同样的方法将此范围再次分成多个更小的范围(256M=2^28,所以最多需要3次就可以将此范围缩小到1,也就找到了中数)。
补充树的知识:
AVL树
最早的平衡二叉树之一。应用相对其他数据结构比较少。windows对进程地址空间的管理用到了avl树。
红黑树
平衡二叉树,广泛用在c++的stl中。如map和set都是用红黑树实现的。
b/b+树
用在磁盘文件组织 数据索引和数据库索引。
trie树(字典树):
用在统计和排序大量字符串,如自动机。
参考:
http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
https://blog.csdn.net/hihozoo/article/details/51248823 (里面Trie树的应用写的很好)
—–正文结束—–
更多精彩文章,请查阅我的博客或关注我的公众号:Rude3Knife
全复习手册文章导航:通过以下两种途径查看
- 关注我的公众号:Rude3Knife 点击公众号下方:技术推文——面试冲刺
- 全复习手册文章导航(CSDN)
知识点复习手册文章推荐
- Java基础知识点面试手册
- Java容器(List、Set、Map)知识点快速复习手册
- Java并发知识点快速复习手册(上)
- Java并发知识点快速复习手册(下)
- Java虚拟机知识点快速复习手册(上)
- Java虚拟机知识点快速复习手册(下)
- 快速梳理23种常用的设计模式
- Redis基础知识点面试手册
- Leetcode题解分类汇总(前150题)
- 面试常问的小算法总结
- 查找算法总结及其部分算法实现Python/Java
- 排序算法实现与总结Python/Java
- HTTP应知应会知识点复习手册(上)
- HTTP应知应会知识点复习手册(下)
- 计算机网络基础知识点快速复习手册
- ……等(请查看全复习手册导航)
关注我
我是蛮三刀把刀,目前为后台开发工程师。主要关注后台开发,网络安全,Python爬虫等技术。
来微信和我聊聊:yangzd1102
Github:https://github.com/qqxx6661
原创博客主要内容
- 笔试面试复习知识点手册
- Leetcode算法题解析(前150题)
- 剑指offer算法题解析
- Python爬虫相关技术分析和实战
- 后台开发相关技术分析和实战
同步更新以下博客
1. Csdn
拥有专栏:
- Leetcode题解(Java/Python)
- Python爬虫实战
- Java程序员知识点复习手册
2. 知乎
https://www.zhihu.com/people/yang-zhen-dong-1/
拥有专栏:
- Java程序员面试复习手册
- LeetCode算法题详解与代码实现
- 后台开发实战
3. 掘金
https://juejin.im/user/5b48015ce51d45191462ba55
4. 简书
https://www.jianshu.com/u/b5f225ca2376
个人公众号:Rude3Knife

如果文章对你有帮助,不妨收藏起来并转发给您的朋友们~