
前言
新开专栏【数据结构拾遗】
本专栏旨在快速了解常见的数据结构和算法。在需要使用到相应算法时,能够帮助你回忆出常用的实现方案并且知晓其优缺点和适用环境。
参考
- 算法(第四版):第五章5.3小节
- http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
- https://www.cnblogs.com/gaochundong/p/string_matching.html#naive_string_matching_algorithm
- http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
子字符串匹配
子字符串匹配算法的定义:
- 文本长度:N
- 模式字符串长度:M
- 有效位移:s
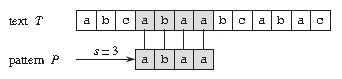
解决字符串匹配的算法有非常多,目前常用的有以下几种:
- 暴力查找
- KMP 算法
- Boyer-Moore算法
- Rabin-Karp指纹字符串查找
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)和匹配(Matching)。所以算法的总运行时间为预处理和匹配的时间的总和。
常用算法
暴力查找
参考:
https://www.cnblogs.com/gaochundong/p/string_matching.html#naive_string_matching_algorithm
朴素的字符串匹配算法又称为暴力匹配算法(Brute Force Algorithm),它的主要特点是:
- 没有预处理阶段;
- 滑动窗口总是后移 1 位;
- 对模式中的字符的比较顺序不限定,可以从前到后,也可以从后到前;
- 匹配阶段需要 O((n - m + 1)m) 的时间复杂度;
- 需要 2n 次的字符比较;
KMP 算法
参考:
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
详细过程:

从左到右匹配,直到匹配到第一个字符相等,如下图所示,然后继续匹配后面的字符。

到了D,发现不对,这是如果暴力法,则直接将模式后移一位,重新匹配。KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。

在查找的一开始根据模式字符串,生成一张《部分匹配表》(Partial Match Table)
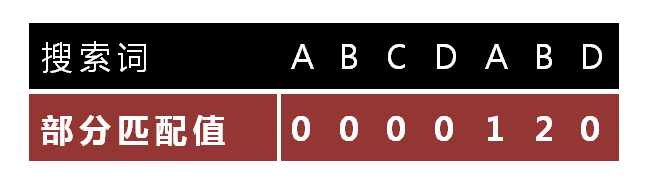
移动位数 = 已匹配的字符数 - 对应的部分匹配值
所以移动为数 = 6 - 2 =4

这个《部分匹配表》如何生成?
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例,
1 | - "A"的前缀和后缀都为空集,共有元素的长度为0; |
Python和Java实现参考自己的博客:
https://blog.csdn.net/qqxx6661/article/details/79583707
Boyer-Moore
参考:
http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
几种常见的字符串匹配算法的性能比较:
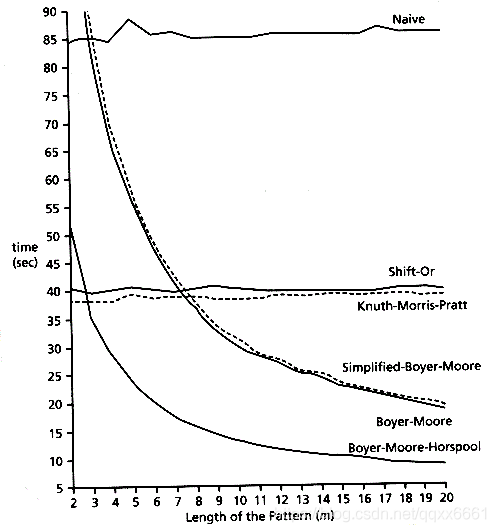
KMP算法并不是效率最高的算法,实际采用并不多。各种文本编辑器的”查找”功能(Ctrl+F),大多采用Boyer-Moore算法。
详细过程:

首先,”字符串”与”搜索词”头部对齐,从尾部开始比较。我们看到,”S”与”E”不匹配。这时,”S”就被称为”坏字符”(bad character),即不匹配的字符。我们还发现,”S”不包含在搜索词”EXAMPLE”之中,这意味着可以把搜索词直接移到”S”的后一位。

依然从尾部开始比较,发现”P”与”E”不匹配,所以”P”是”坏字符”。但是,”P”包含在搜索词”EXAMPLE”之中。所以,将搜索词后移两位,两个”P”对齐。
“坏字符规则”:后移位数 = 坏字符的位置 - 搜索词中的上一次出现位置(如果”坏字符”不包含在搜索词之中,则上一次出现位置为 -1)
上图中,比较的是P和E,出现在第6位(0开始),然后P上一次位置是4,所以6-4=2
接着继续,一直比较到M:


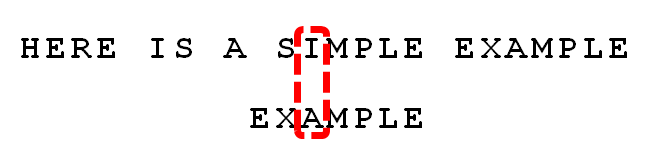
根据”坏字符规则”,此时搜索词应该后移 2 - (-1)= 3 位。问题是,此时有没有更好的移法?
比较前面一位,”MPLE”与”MPLE”匹配。我们把这种情况称为”好后缀”(good suffix),即所有尾部匹配的字符串。注意,”MPLE”、”PLE”、”LE”、”E”都是好后缀
“好后缀规则”:后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
这个规则有三个注意点:
(1)”好后缀”的位置以最后一个字符为准。假定”ABCDEF”的”EF”是好后缀,则它的位置以”F”为准,即5(从0开始计算)。
(2)如果”好后缀”在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,”EF”在”ABCDEF”之中只出现一次,则它的上一次出现位置为-1(即未出现)。
(3)如果”好后缀”有多个,则除了最长的那个”好后缀”,其他”好后缀”的上一次出现位置必须在头部。比如,假定”BABCDAB”的”好后缀”是”DAB”、”AB”、”B”,请问这时”好后缀”的上一次出现位置是什么?回答是,此时采用的好后缀是”B”,它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个”好后缀”只出现一次,则可以把搜索词改写成如下形式进行位置计算”(DA)BABCDAB”,即虚拟加入最前面的”DA”。
回到上文的这个例子。此时,所有的”好后缀”(MPLE、PLE、LE、E)之中,只有”E”在”EXAMPLE”还出现在头部,所以后移 6 - 0 = 6位。
可以看到,”坏字符规则”只能移3位,”好后缀规则”可以移6位。所以,Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
Boyer–Moore 算法的精妙之处在于,其通过两种启示规则来计算后移位数,且其计算过程只与模式 P 有关,而与文本 T 无关。因此,在对模式 P 进行预处理时,可预先生成 “坏字符规则之向后位移表” 和 “好后缀规则之向后位移表”,在具体匹配时仅需查表比较两者中最大的位移即可。
Rabin-Karp
参考:
https://www.cnblogs.com/tanxing/p/6049179.html
首先计算模式字符串的散列函数, 如果找到一个和模式字符串散列值相同的子字符串, 那么继续验证两者是否匹配.
这个过程等价于将模式保存在一个散列表中, 然后在文本中的所有子字符串查找. 但不需要为散列表预留任何空间, 因为它只有一个元素.
基本思想
长度为M的字符串对应着一个R进制的M位数, 为了用一张大小为Q的散列表来保存这种类型的键, 需要一个能够将R进制的M位数转化为一个0到Q-1之间的int值散列函数, 这里可以用除留取余法.
举个例子, 需要在文本 3 1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 查找模式 2 6 5 3 5, 这里R=10, 取Q=997, 则散列值为
1 | 2 6 5 3 6 % 997 = 613 |
然后计算文本中所有长度为5的子字符串并寻找匹配
1 | 3 1 4 1 5 % 997 = 508 |
计算散列函数
在实际中,对于5位的数值, 只需要使用int就可以完成所有需要的计算, 但是当模式长度太大时, 我们使用Horner方法计算模式字符串的散列值
2 % 997 = 2
2 6 % 997 = (2*10 + 6) % 997 = 26
2 6 5 % 997 = (26*10 + 5) % 997 = 265
2 6 5 3 % 997 = (265*10 + 3) % 997 = 659
2 6 5 3 5 % 997 = (659*10 + 5) % 997 = 613
这里关键的一点就是在于不需要保存这些数的值, 只需保存它们除以Q之后的余数.
取余操作的一个基本性质是如果每次算术操作之后都将结果除以Q并取余, 这等价于在完成所有算术操作之后再将最后的结果除以Q并取余.
算法实现:
构造函数为模式字符串计算了散列值patHash并在变量中保存了R^(M-1) mod Q的值, hashSearch()计算了文本前M个字母的散列值并和模式字符串的散列值比较, 如果没有匹配, 文本指针继续下移一位, 计算新的散列值再次比较,知道成功或结束.
Java代码:
https://www.cnblogs.com/tanxing/p/6049179.html
蒙特卡洛算法和拉斯维加斯算法区别:

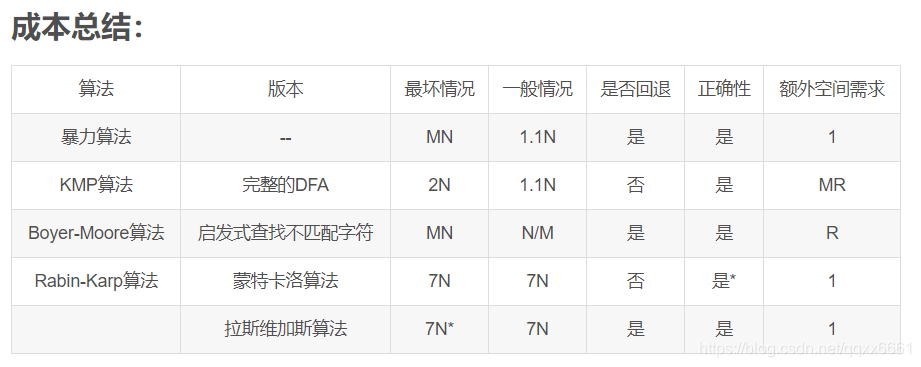
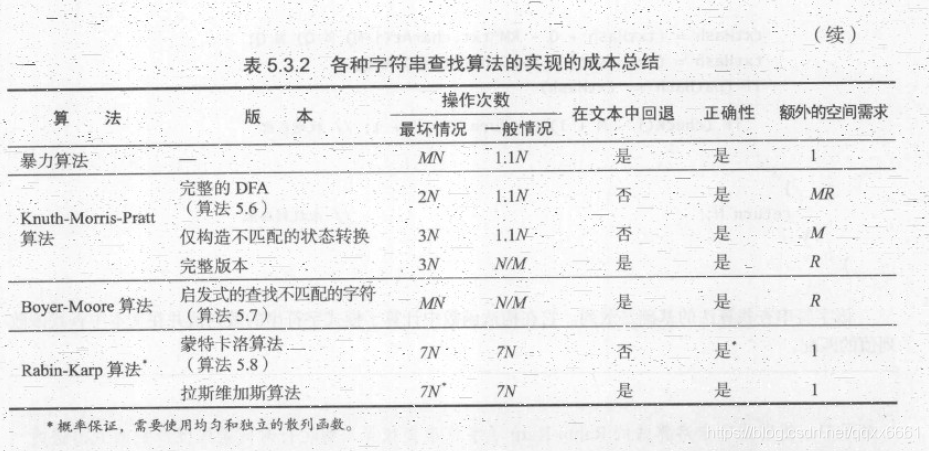
总结
优点:
- 暴力查找算法:实现简单且在一般情况下工作良好(Java的String类型的indexOf()方法就是采用暴力子字符串查找算法);
- Knuth-Morris-Pratt算法能够保证线性级别的性能且不需要在正文中回退;
- Boyer-Moore算法的性能一般情况下都是亚线性级别;
- Rabin-Karp算法是线性级别;
缺点:
- 暴力查找算法所需时间可能和NM成正比;
- Knuth-Morris-Pratt算法和Boyer-Moore算法需要额外的内存空间;
- Rabin-Karp算法内循环很长(若干次算术运算,其他算法都只需要比较字符);
关注我
我是蛮三刀把刀,后端开发。主要关注后端开发,数据安全,爬虫等方向。微信:yangzd1102
Github:@qqxx6661
个人博客:
原创博客主要内容
- Java知识点复习全手册
- Leetcode算法题解析
- 剑指offer算法题解析
- SpringCloud菜鸟入门实战系列
- SpringBoot菜鸟入门实战系列
- Python爬虫相关技术文章
- 后端开发相关技术文章
个人公众号:Rude3Knife

如果文章对你有帮助,不妨收藏起来并转发给您的朋友们~
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3mmnmn9r2ewwg