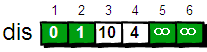
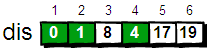
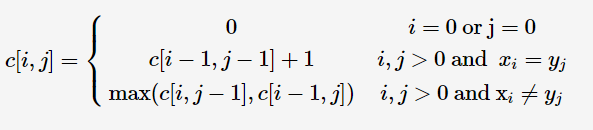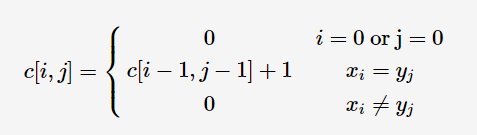def triangles(): N=[1] while True: yield N N.append(0) N=[N[i-1] + N[i] for i in range(len(N))] n=0 for t in triangles(): print(t) n=n+1 if n == 10: break
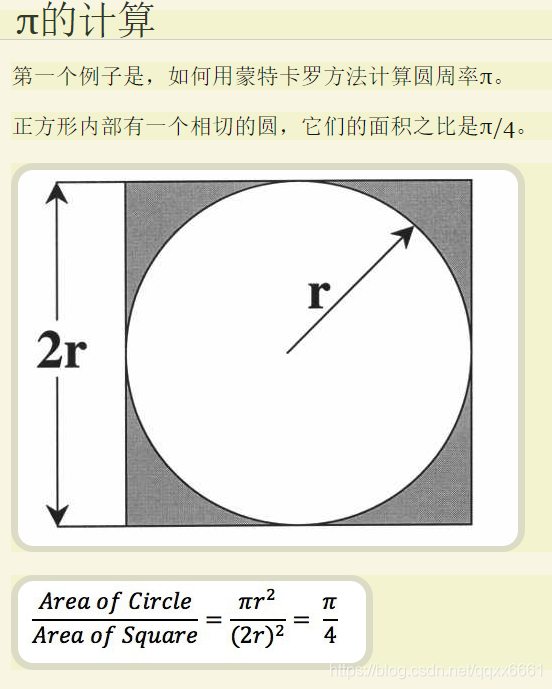
from random import random from math import sqrt from time import clock #计算程序运行时间 DARTS=1200 #抛洒点的个数 #DARTS=5000 #DARTS=20000 #DARTS=1000000 hists=0 #抛洒点在1/4(半径为1)圆内点的个数 clock() for i in range(1,DARTS): x,y=random(),random() dict=sqrt(x**2+y**2) if dict<=1.0: hists=hists+1 #随机设点,若抛洒点在1/4圆内,则dice+1 pi=4*(hists/DARTS) print("PI的值是 %s" %pi) print("程序运行的时间是 %-5.5ss" %clock())
/** * Karatsuba乘法 */ public static long karatsuba(long num1, long num2){ //递归终止条件 if(num1 < 10 || num2 < 10) return num1 * num2;
// 计算拆分长度 int size1 = String.valueOf(num1).length(); int size2 = String.valueOf(num2).length(); int halfN = Math.max(size1, size2) / 2;
/* 拆分为a, b, c, d */ long a = Long.valueOf(String.valueOf(num1).substring(0, size1 - halfN)); long b = Long.valueOf(String.valueOf(num1).substring(size1 - halfN)); long c = Long.valueOf(String.valueOf(num2).substring(0, size2 - halfN)); long d = Long.valueOf(String.valueOf(num2).substring(size2 - halfN));
// 计算z2, z0, z1, 此处的乘法使用递归 long z2 = karatsuba(a, c); long z0 = karatsuba(b, d); long z1 = karatsuba((a + b), (c + d)) - z0 - z2;
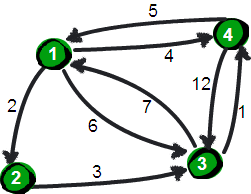
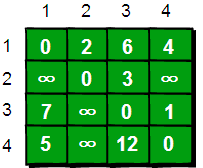
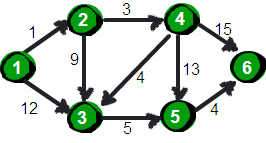
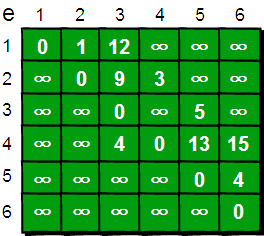
def get_edgenum(self): count = 0 for i in range(self.nodenum): for j in range(i): if self.maps[i][j] > 0 and self.maps[i][j] < 9999: count += 1 return count
def kruskal(self): res = [] if self.nodenum <= 0 or self.edgenum < self.nodenum - 1: return res edge_list = [] for i in range(self.nodenum): for j in range(i, self.nodenum): if self.maps[i][j] < 9999: edge_list.append([i, j, self.maps[i][j]]) # 按[begin, end, weight]形式加入 edge_list.sort(key=lambda a: a[2]) # 已经排好序的边集合
group = [[i] for i in range(self.nodenum)] for edge in edge_list: for i in range(len(group)): if edge[0] in group[i]: m = i if edge[1] in group[i]: n = i if m != n: res.append(edge) group[m] = group[m] + group[n] group[n] = [] return res
def prim(self): res = [] if self.nodenum <= 0 or self.edgenum < self.nodenum - 1: return res res = [] seleted_node = [0] candidate_node = [i for i in range(1, self.nodenum)]
while len(candidate_node) > 0: begin, end, minweight = 0, 0, 9999 for i in seleted_node: for j in candidate_node: if self.maps[i][j] < minweight: minweight = self.maps[i][j] begin = i end = j res.append([begin, end, minweight]) seleted_node.append(end) candidate_node.remove(end) return res
if __name__ == "__main__": # 读取第一行的n n = int(sys.stdin.readline().strip('')) cun_list = list(map(int,sys.stdin.readline().strip('').split(' '))) dp = [[0 for __ in range(n)] for __ in range(n)] for i in range(n): for j in range(n): if i == j: dp[i][j] = 0 continue dp[i][j] = max(cun_list[i],cun_list[j])